[🇨🇳 简体中文](./README.md) | [🇬🇧 English](./README_en.md)
# 🦞 龙虾问数 (DataClaw)
> **释放你的数据潜能,让分析像养龙虾一样简单爽快!** 🌊📊
> 龙虾问数 (DataClaw) 是一个智能的、AI 驱动的数据分析平台。通过自然语言与你的数据对话,瞬间生成可视化图表,轻松搭建仪表盘——从此告别繁琐的 SQL 语句!
***
## ✨ 为什么选择龙虾问数?
受够了为了画个简单的柱状图而写半天复杂的 SQL 语句吗?龙虾问数就是你的私人数据科学家。借助强大的大语言模型 (LLM) 和智能 Agent 工作流,它能将你的自然语言提问精准转化为数据库查询,提取数据,并即时渲染出美观的可视化图表。
无论你是要查询庞大的 Supabase/PostgreSQL 数据库,还是随手丢进一个 CSV 文件,龙虾问数都能轻松拿捏!🚀
## 🌟 核心特性
- **🗣️ 自然语言转 SQL**: 用大白话提问!它能理解你的数据表结构,生成准确的 SQL,甚至在报错时进行自我纠正 (Self-correction)。
- **📚 智能知识库检索 (RAG)**: 支持上传 Word、PPT、PDF 等多种格式文档,通过向量检索增强回答,让你的私有文档“开口说话”。
- **📈 即时数据可视化**: 拒绝枯燥的生肉表格,根据数据特征自动生成交互式图表。
- **🗂️ 动态多数据源**: 无缝连接 PostgreSQL、Supabase,以及本地 CSV/Excel 文件上传解析。
- **🧠 灵活的模型接入**: 原生集成 LiteLLM,支持随插随用 OpenAI、DeepSeek、智谱、通义千问 (DashScope)、火山引擎或任何兼容的 LLM 提供商。
- **🛠️ 强大的 Agent 技能拓展**: 基于核心 `nanobot`框架(`OpenClaw`的精简版)构建。支持通过斜杠命令 (`/`) 快速调用自定义工具 (Skills),完美贴合特定业务逻辑。
- **📊 可定制仪表盘 (Dashboard)**: 一键将对话中生成的图表固定到看板,拖拽布局,随时查看核心指标。
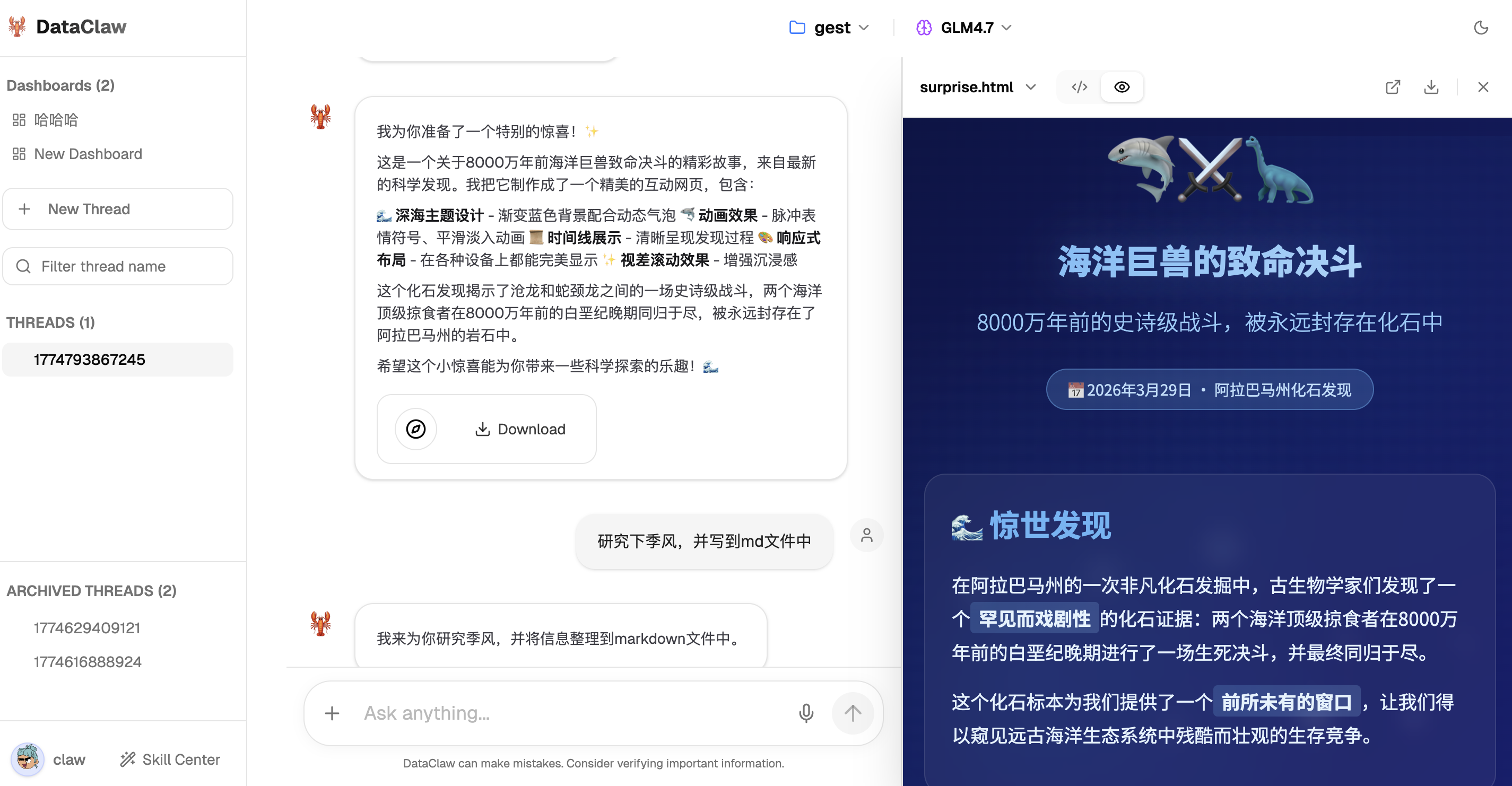
- **📦 智能产物管理 (Artifact)**: 自动提取对话中生成的各种文件(网页报告、PDF、PPT、图片等),提供一键内嵌预览与下载功能,让成果触手可及。
***
## 📸 界面预览
💬 对话式分析界面

📊 可定制仪表盘
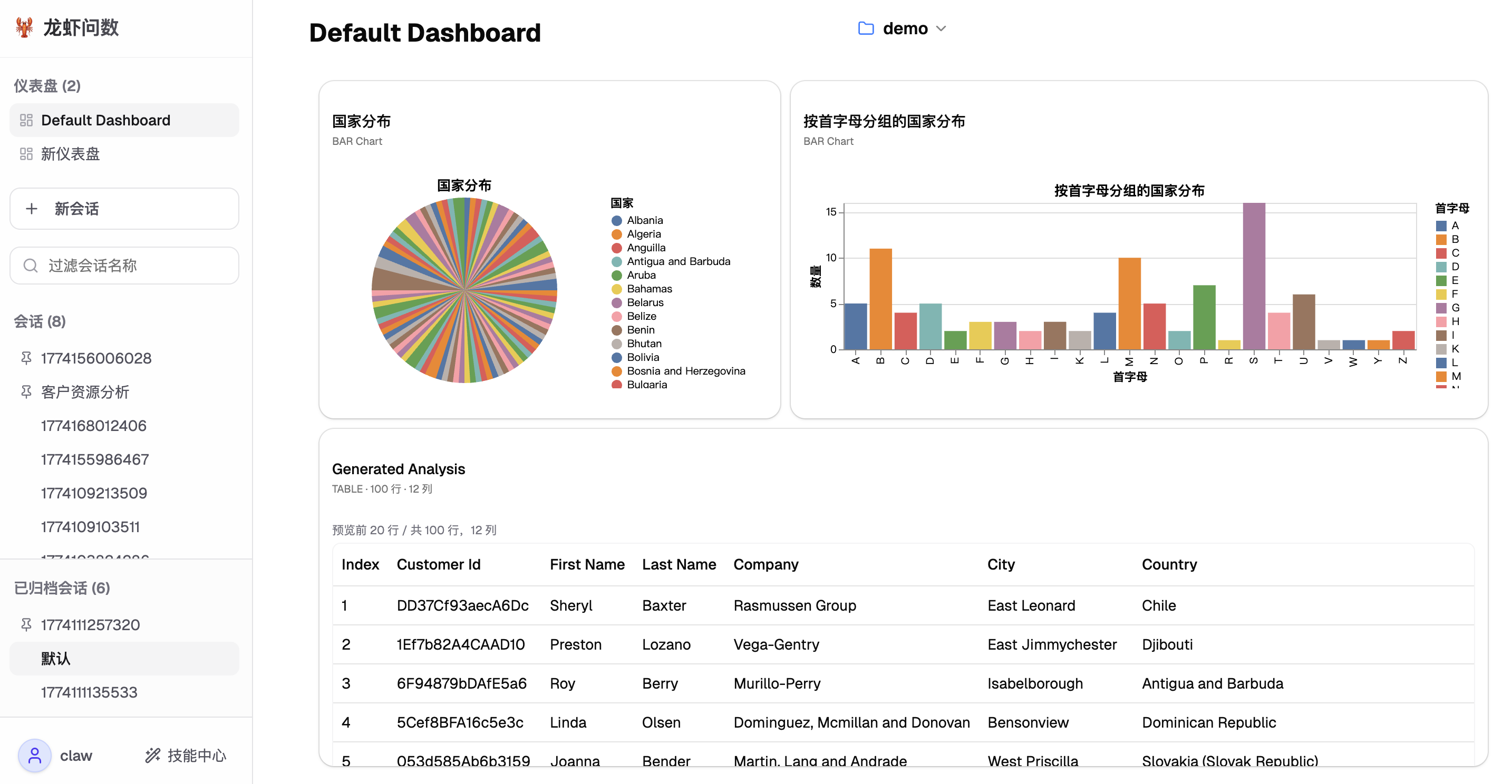
📚 智能知识库问答
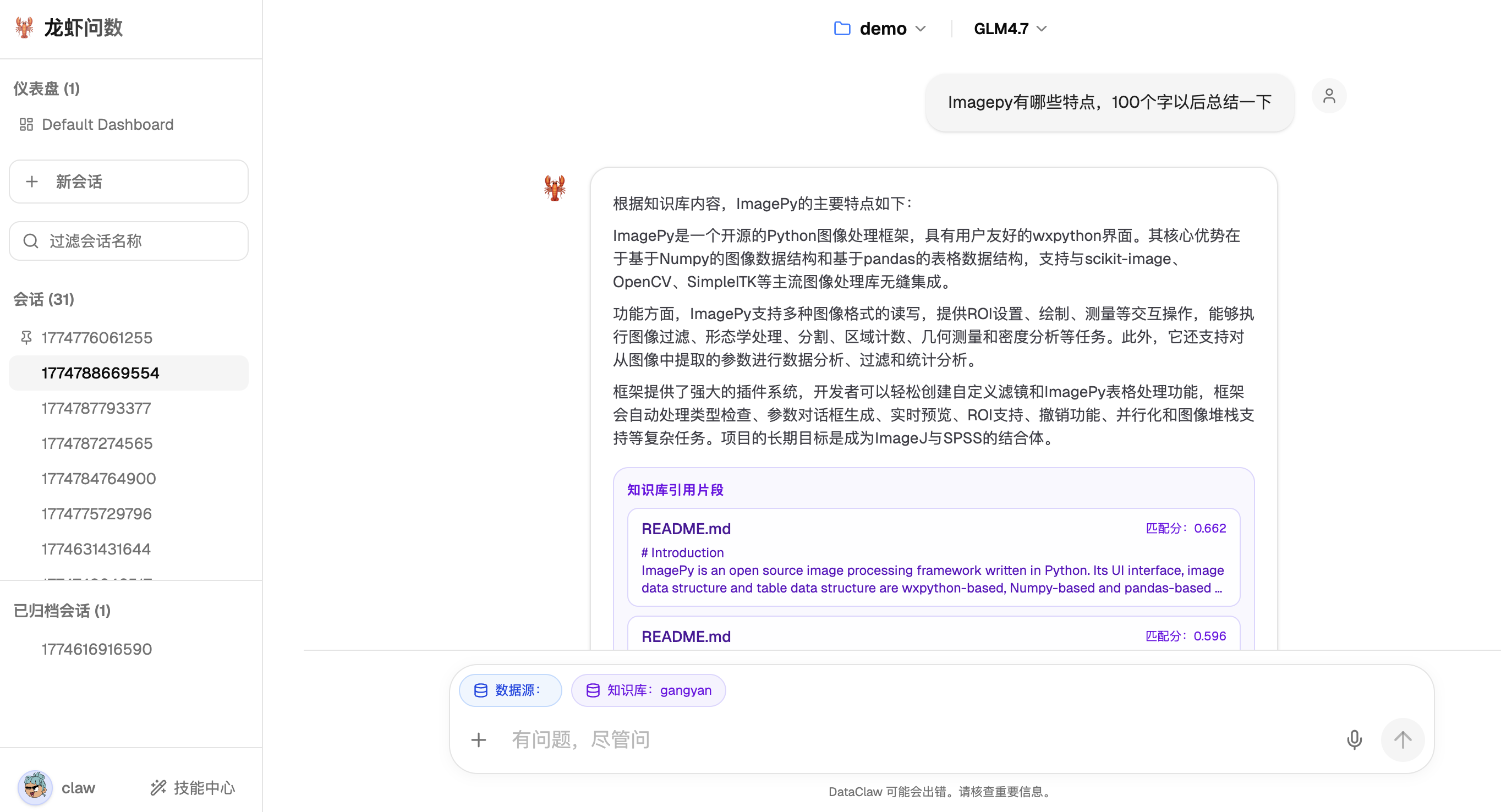
📦 智能产物预览 (Artifact)
## 🏗️ 项目架构
DataClaw 的架构主要由四个核心部分组成:
1. **`frontend/`** 🎨: 闪亮的外壳。基于 **React 19**、**Vite**、**TailwindCSS** 和 **Zustand** 构建。拥有类似微信/ChatGPT的对话界面、支持流式思考过程渲染以及交互式图表展示。
2. **`backend/`** ⚙️: 强健的肌肉。一个 **FastAPI** 后端服务,负责管理项目、数据源连接、用户会话持久化以及作为 API 网关。
3. **`nanobot/`** 🧠: 智慧的大脑。核心的 AI Agent 框架,负责处理意图路由、NL2SQL 转换、Schema 缓存管理以及与 LLM 的底层交互。
4. **`data/`** 🗄️: 运行时数据目录。与代码目录解耦,存放上传文件、会话、技能工作区、报告与配置缓存。
```mermaid
graph TD
User([👤 用户 / 浏览器]) -->|HTTP / WebSocket| Frontend
subgraph DataClaw 系统
Frontend[🎨 frontend
React / Vite / Zustand]
Backend[⚙️ backend
FastAPI / 会话 / 数据源管理]
Nanobot[🧠 nanobot
AI Agent / NL2SQL / RAG]
Data[🗄️ data
运行时文件 / 产物缓存]
Frontend -->|REST API / SSE| Backend
Backend <-->|任务委派 / 函数调用| Nanobot
Backend -->|读写| Data
Nanobot -->|读写| Data
end
subgraph 外部服务与数据
LLM([🤖 LLM 供应商
OpenAI, DeepSeek, 智谱等])
DB[(📊 数据源
PostgreSQL, CSV, Supabase等)]
end
Nanobot <-->|Prompt / Completion| LLM
Backend <-->|连接 / 查询| DB
Nanobot -.->|Schema 检索 / SQL 执行| DB
```
***
## 🚀 快速开始
准备好大显身手了吗?让我们把龙虾问数在你的本地跑起来!
### 1. 配置环境变量 🔧
在项目根目录下,复制并重命名环境配置模板:
```bash
cp .env.example .env
```
请记得编辑根目录下的 `.env` 文件,填入你的实际配置(如 QQ 邮箱 SMTP 授权码等)。
> **QQ 邮箱获取 SMTP 授权码最新教程:**
> 1. 登录 QQ 邮箱网页版 (mail.qq.com)
> 2. 点击页面顶部的“设置” -> “账号”选项卡
> 3. 向下滚动找到“POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务”
> 4. 确保“POP3/SMTP服务”已点击“开启”
> 5. 点击下方的“生成授权码”,使用手机 QQ 扫码或按提示发送短信
> 6. 验证通过后将获得一串 **16位随机字母组合**,将其复制填入 `.env` 文件中的 `SMTP_PASSWORD` 字段
### 2. 生产模式(推荐,无需 Node.js)📦
#### 2.1 打包 wheel(产物输出到根目录 `dist/`)
如需自行打包发布,请按以下顺序执行:先构建前端,再构建后端 wheel,并将产物输出到项目根目录 `dist/`(与 `backend/` 同级)。
```bash
# 1) 构建前端静态资源
cd frontend
npm install
npm run build
# 2) 构建后端 wheel,并输出到根目录 dist/
cd ../backend
uv build --wheel --out-dir ../dist
```
构建完成后,wheel 位于项目根目录 `dist/`,例如 `dist/dataclaw-0.1.0-py3-none-any.whl`。
#### 2.2 安装与启动(使用 2.1 的 wheel)
请确保你已安装 Python 3.11+ 与 `uv`。生产模式使用已打包的 wheel(2.1 产物),无需安装 Node.js。
```bash
# 在项目根目录创建独立虚拟环境(不依赖 source 激活)
uv venv .venv
source .venv/bin/activate
# 安装已打包的 wheel 到该虚拟环境
uv pip install ./dist/dataclaw-*.whl
# 启动服务(默认 http://127.0.0.1:8000)
dataclaw start
```
常用服务控制命令(同一虚拟环境):
```bash
# 查看运行状态
dataclaw status
# 自定义监听地址/端口
dataclaw start --host 0.0.0.0 --port 8000
# 停止服务
dataclaw stop
```
可选环境变量:
```bash
export DATA_ROOT=/absolute/path/to/data
```
若未设置,默认使用仓库根目录下的 `data/`。服务状态文件与日志默认位于 `DATA_ROOT/run/`。
### 3. 开发模式(需要 Node.js)🧪
如果你要调试代码,请使用开发模式。开发模式直接跑源码,不依赖 wheel。
```bash
cd backend
# 安装/同步后端依赖(会在 backend/.venv 中准备环境)
uv sync
# 启动 FastAPI 服务器
uv run uvicorn main:app --reload --port 8000
```
```bash
cd frontend
# 安装依赖(仅开发模式需要 Node.js)
npm install
# 启动 Vite 开发服务器
npm run dev
```
*提示:请确保* *`nanobot`* *核心库已根据项目工作区的要求正确链接或以可编辑模式 (editable mode) 安装。*
### 4. 语音识别服务(可选)🎙️
若你希望使用聊天输入框中的语音输入能力,请单独启动 `whisper` 服务:
```bash
cd whisper
uv venv
source .venv/bin/activate
uv pip install -r requirements.txt
uv run python main.py
```
默认服务地址:`http://localhost:8001`
健康检查接口:`GET /health`
前端配置方式:
1. 点击左下角用户名,打开菜单;
2. 进入「语音输入配置」;
3. 填写服务地址(例如 `http://localhost:8001`);
4. 点击「测试连接」通过后保存。
### 5. 初始账号配置 👤
系统首次注册的用户将自动成为管理员。您可以在登录页面直接点击“注册”按钮创建您的管理员账号(例如:用户名 `admin`,密码 `admin`),随后即可登录并管理项目、数据源和用户。
### 6. A2A 模式使用指南 🤖
A2A(Agent2Agent)用于让 DataClaw 把任务委托给远端 Agent,并保持任务可跟踪(状态流、产物流、取消、重试)。
#### 6.1 在前端启用 A2A(推荐)
1. 进入 **Skills** 页面,切到 **A2A** 标签页。
2. 点击新增远端 Agent,填写:
- `name`: 远端 Agent 名称
- `base_url`: 远端 DataClaw/A2A 网关地址(如 `https://agent-b.example.com`)
- `auth_scheme`: `none` 或 `bearer`
- `auth_token`: 当 `auth_scheme=bearer` 时填写
3. 点击健康检查,确认 `healthy=true`。
4. 回到聊天页,开启 **A2A Mode**,选择 `route_mode` 与目标 Agent 后发送问题。
5. 在消息卡片与 A2A 任务面板中查看 `SUBMITTED/WORKING/COMPLETED/FAILED` 等状态,可执行取消与重试。
`route_mode` 建议:
- `auto`: 按项目灰度配置与策略自动决策
- `local`: 强制本地执行
- `a2a`: 强制远端 A2A 执行(需选远端 Agent)
- `a2a_first`: 先远端,失败按回退链执行
- `local_first`: 先本地,按需再回退
#### 6.2 API 示例(生产常用)
以下示例假设服务地址为 `http://127.0.0.1:8000`,并已获取登录令牌 `${TOKEN}`。
**示例 1:查看本机 A2A Agent Card**
```bash
curl -H "Authorization: Bearer ${TOKEN}" \
http://127.0.0.1:8000/api/v1/a2a/agent-card
```
**示例 2:注册远端 Agent**
```bash
curl -X POST http://127.0.0.1:8000/api/v1/a2a/remote-agents \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"project_id": 1,
"name": "Agent-B",
"base_url": "https://agent-b.example.com",
"auth_scheme": "bearer",
"auth_token": "remote-agent-token"
}'
```
**示例 3:以 A2A 优先模式发起任务**
```bash
curl -X POST http://127.0.0.1:8000/api/v1/a2a/messages/send \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"project_id": 1,
"message": "请分析最近30天订单转化趋势并给出建议",
"session_id": "chat:demo-a2a",
"remote_agent_id": 3,
"route_mode": "a2a_first",
"fallback_chain": ["a2a", "local", "mcp"],
"idempotency_key": "demo-a2a-001"
}'
```
返回结果中的 `task.id` 可用于订阅与管理任务。
**示例 4:订阅任务流(SSE)**
```bash
curl -N -H "Authorization: Bearer ${TOKEN}" \
http://127.0.0.1:8000/api/v1/a2a/tasks//subscribe
```
你会收到类似事件:
- `TaskStatusUpdateEvent`(状态变更)
- `TaskArtifactUpdateEvent`(产物更新)
- `done`(流结束)
**示例 5:取消任务**
```bash
curl -X POST -H "Authorization: Bearer ${TOKEN}" \
http://127.0.0.1:8000/api/v1/a2a/tasks//cancel
```
**示例 6:为任务配置 Webhook 回调(离线接收结果)**
```bash
curl -X POST http://127.0.0.1:8000/api/v1/a2a/tasks//webhooks \
-H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"target_url": "https://your-system.example.com/a2a/webhook",
"secret": "your-webhook-secret",
"auth_header": "Bearer your-internal-token"
}'
```
#### 6.3 一个完整实战流程
场景:你有一个“本地数据分析 Agent”,还接入了“外部行业知识 Agent-B”。
1. 在 Skills -> A2A 注册 `Agent-B` 并完成健康检查。
2. 在聊天页开启 A2A,选择 `route_mode=a2a_first`。
3. 输入问题:
`请结合外部行业知识与本地销量数据,生成本季度增长策略。`
4. 系统先尝试委托给 `Agent-B`;若远端异常则按回退链降级到本地/MCP。
5. 在任务面板查看状态流与最终产物,必要时可取消或重试。
生产建议:
- 对业务侧请求始终传 `idempotency_key`,避免重复任务。
- 为长任务配置 webhook,避免客户端断线丢失进度。
- 在项目级 rollout 配置灰度比例,先小流量启用 A2A 再全量放开。
#### 6.4 本地调试 A2A(双实例联调)
推荐在本机同时启动两个后端实例:
- 实例 A(调用方):`http://127.0.0.1:8000`
- 实例 B(被调用远端 Agent):`http://127.0.0.1:8001`
分别用两个终端启动(建议使用不同 `DATA_ROOT`,避免数据目录冲突):
```bash
# 终端1:实例 A
cd backend
DATA_ROOT=/tmp/dataclaw-a uv run uvicorn main:app --reload --port 8000
```
```bash
# 终端2:实例 B
cd backend
DATA_ROOT=/tmp/dataclaw-b uv run uvicorn main:app --reload --port 8001
```
然后在两个实例分别注册并登录,拿到 token:
```bash
# 分别注册(每个实例首次注册用户会成为管理员)
curl -X POST http://127.0.0.1:8000/api/v1/auth/register \
-H "Content-Type: application/json" \
-d '{"username":"admin_a","email":"a@test.com","password":"admin12345"}'
curl -X POST http://127.0.0.1:8001/api/v1/auth/register \
-H "Content-Type: application/json" \
-d '{"username":"admin_b","email":"b@test.com","password":"admin12345"}'
# 登录并保存 token
TOKEN_A=$(curl -s -X POST http://127.0.0.1:8000/api/v1/auth/login \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "username=admin_a&password=admin12345" | jq -r '.access_token')
TOKEN_B=$(curl -s -X POST http://127.0.0.1:8001/api/v1/auth/login \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "username=admin_b&password=admin12345" | jq -r '.access_token')
```
最后,在实例 A 中把实例 B 注册成远端 Agent(`auth_token` 使用 `TOKEN_B`):
```bash
curl -X POST http://127.0.0.1:8000/api/v1/a2a/remote-agents \
-H "Authorization: Bearer ${TOKEN_A}" \
-H "Content-Type: application/json" \
-d "{
\"project_id\": 1,
\"name\": \"local-agent-b\",
\"base_url\": \"http://127.0.0.1:8001\",
\"auth_scheme\": \"bearer\",
\"auth_token\": \"${TOKEN_B}\"
}"
```
完成后即可在实例 A 发起 A2A 任务、订阅任务流、取消任务,完成本地端到端联调。
***
## 🔌 数据源配置说明
DataClaw 支持连接多种类型的数据源,以满足不同场景的分析需求。你可以在界面的 **Data Sources** 菜单中点击 **+** 新建并配置它们。以下是常见数据源的详细接入指南:
▶ PostgreSQL (pgsql)
连接标准的关系型数据库。你既可以通过表单填充分散的参数,也可以直接粘贴完整的 Connection String。
- **Host**: 数据库的主机地址。如果你是在本地电脑运行了数据库(如使用 pgAdmin),请填入 `127.0.0.1`(不要填 `localhost`,以避免 Unix Socket 解析错误)。
- **Port**: 默认一般为 `5432`。
- **Database**: 你要连接的具体数据库名称。
- **Username / Password**: 数据库的认证凭据(默认用户通常是 `postgres`)。
- **Connection String (可选)**: 也可以直接输入类似 `postgresql://postgres:你的密码@127.0.0.1:5432/你的数据库名` 的字符串,它将覆盖上述单独的输入框配置。
▶ Supabase
专门针对 Supabase 云端 PostgreSQL 数据库优化的连接方式,强制开启 SSL 且默认使用连接池以提高稳定性。
- 推荐直接使用 **Connection String** 配置:
进入你的 Supabase 项目控制台 -> `Project Settings` -> `Database` -> `Connection string` -> 选择 `URI` 选项卡。
复制那串类似 `postgresql://postgres.[project-ref]:[password]@aws-0-[region].pooler.supabase.com:6543/postgres?sslmode=require` 的链接并填入。
- *注意*: Supabase 默认开启了 Transaction Pooler(端口 6543)。如果想要直连(Direct connection),请将端口改为 `5432`,并确保 URL 中包含 `sslmode=require`。
▶ SQLite
轻量级的本地文件型数据库,非常适合快速测试或分析单机应用数据。
- **File Upload**: 你可以直接点击按钮,从本地上传 `.db`、`.sqlite` 或 `.sqlite3` 后缀的数据库文件。文件会被安全地保存在服务端的上传目录中供分析使用。
- **File Path (进阶)**: 如果服务部署在服务器上,且 SQLite 文件已存在于服务器的某个绝对路径中,你也可以直接在输入框中填入该文件的绝对路径(如 `/data/my_app.db`)。
▶ CSV
最常见的数据交换格式,即插即用,无需复杂的数据库配置。
- **File Upload**: 与 SQLite 类似,点击按钮选择本地的 `.csv` 文件上传即可。系统会在后台利用 DuckDB 或 Pandas 等引擎将其虚拟化为一个可供 SQL 查询的表。
- 上传成功后,在对话界面中,你可以直接把这个 CSV 文件当作一张数据库表来“提问”!
***
## 🤝 参与贡献
有个好点子?发现了一个 Bug?非常欢迎你的加入!随时可以提交 Issue 或 Pull Request。让我们一起让数据分析变得更加有趣!
***
## 💖 特别鸣谢
DataClaw 的开发深受以下优秀开源项目的启发,特此致谢:
- [WrenAI](https://github.com/Canner/WrenAI): 强大的 Text-to-SQL 解决方案,其架构和思路给了我们很大的启发。
- [Aix-DB](https://github.com/apconw/Aix-DB): 在智能数据分析和交互式体验方面提供了极好的参考。